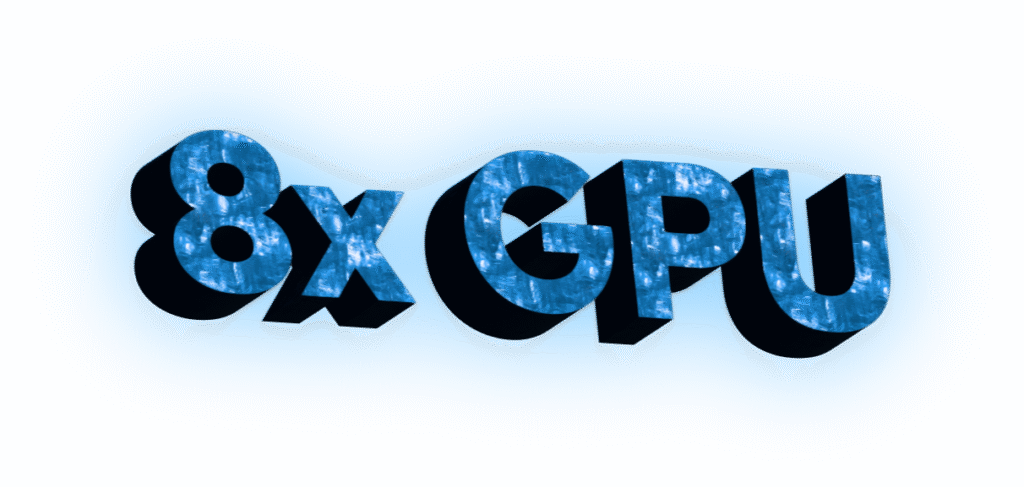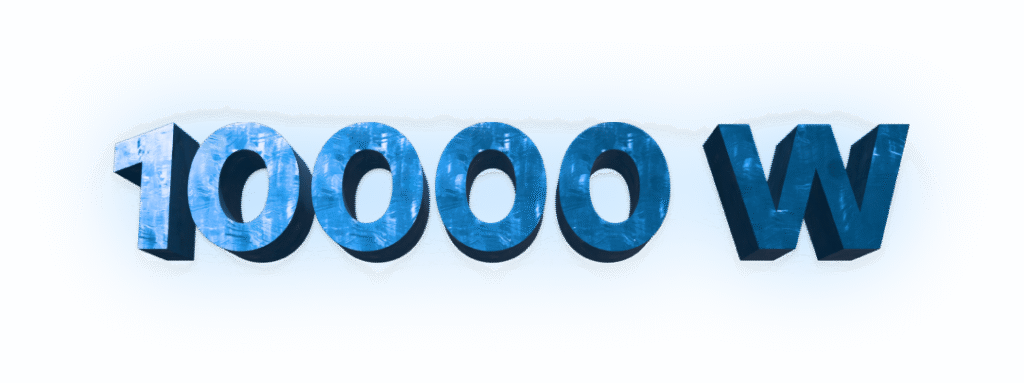Total power delivery of 10,000 watts ensures all 8 high-powered NVIDIA accelerators receive maximum, sustained energy, even under the most extreme loads. This ample supply eliminates power throttling, guaranteeing continuous peak performance for deep learning and
high-fidelity simulations across the entire cluster.